

I Downloaded the AI Murder Code: Here’s What I Found
How AI creates knowledge, but first, we have to talk about why "Alex" killed his boss

Earlier this week, the CEO of Nvidia Jensen Huang appeared on The Joe Rogan Experience. In a short clip that appeared online, he said “In the future, in…maybe two or three years, 90% of the world’s knowledge will likely be generated by AI.” It’s a striking statement, and there’s room for debate, but he’s probably right.
This kind of tech hubris is right up Heidi N Moore’s street. She’s a writer for Yahoo, WSJ, and The Guardian. Quoting the clip she said “as a reminder: AI cannot generate knowledge. It cannot create knowledge. It cannot find new information. It can only mix information that has already been found and written and input into computers by humans.”
42,000 likes, 8,100 retweets and 1,100,000 views at the time of writing, on a statement that’s wrong. I guess I’m a little jealous of those numbers, can we all perhaps endeavour to try and set the record straight here? AI can generate new knowledge, it has already done so several times, and it’s only to going to accelerate.
I don’t mean to pick on Heidi (I’m sure there’s lots we agree on!) instead my intention is to explore this misconception and shed light on a more optimistic perspective, though we’ll first have to take a journey through blackmail and murder… Let’s get started shall we?
Heidi’s statement is correct if you consider Large Language Models in total isolation from everything else. It’s a bit like saying that pumps can’t move water, if you ignore pipes, and cars can’t carry passengers if you ignore roads. When we plug LLMs into things, they can indeed produce new knowledge and will eventually do so at a dizzying rate. To demonstrate that AI can infact create new knowledge, here is a great demonstration from Microsoft showing exactly that. Their system, “Microsoft Discovery” autonomously invented a better CPU coolant that does not use forever chemicals. New knowledge.
In the video, you’ll see that John Link says their system achieved this by “reasoning over knowledge, generating hypotheses, and running experiments”. Their suite of AI agents screened hundreds of thousands of potential molecular candidates based on specific criteria. What would normally have taken years of human led research was completed in 200 hours. After it was done researching and experimenting, the system produced a few molecular candidates that could have the properties they wanted. The team then synthesized the molecule, and lo and behold, it worked. Humanity is now in possession of a new CPU coolant that does not rely on forever chemicals.
So how on earth is this possible? Do you just ask the AI ‘hey! Invent me some new weird liquid!” To understand what’s going on here, we’ll first have to explore how “AI” works, and from there, all will become clear.
The biggest thing to clear up is this. Your AI isn’t AI. Your favourite “AI tools” are actually just a very powerful large language model with a few extra gadgets. Large Language Models (LLMs) are very different to AI, but they’re still very capable. What LLMs do is predict the next most likely word from all the previous words. They do this over and over again until you tell them to stop. Read and understand all the words, predict the most likely next word, repeat.
To do this, they use a statistical distillation of a lot of writing. Imagine you converted all written language into probabilities instead of articles or books. An LLM is Large in that it’s a Large amount of data, it’s Language in that it’s… words, and it’s a Model in that it’s no longer just words, it’s words and phrases modelled into probabilities.
Phew.
Outside of the very complex ‘how’ it works, it’s what it does which is easier to understand and reason about. It’s helpful to have a mental model, so imagine LLMs as simulators running this task: “If the person we invoked were writing these words, what would most likely appear next?”
The cat sat on the ______
As weird as it may be, when the statistical model powering this has read and categorised almost everything, and its able to work out the meaning of words in context, it produces barely believable results. That’s why our shorthand for this system is now “AI” because the things that emerge out of it are so useful, so uncanny and intelligent, and so believable that it almost feels like magic. But your “AI” is actually best understood as a high powered simulator. Whatever statement you put into it, it does a great job simulating more of it.
For people with a good theory of mind, you can use LLMs to ‘jump into’ lots of different perspectives and knowledge modes just by prompting the LLM to play those parts. “You are [some kind of character or archetype], please read this and tell me what you think?” You can steel-man positions you disagree with, red team your own perspective, or learn some of the holes in a particular idea.
So isn’t Heidi right? The AI is just simulating what it thinks some other person already believes? From the standpoint of “I write my question into this search bar and get the answer”, Heidi is correct. Because in that situation, the AI is calculating what someone answering that question is most likely to say. As all readers of The Digger now know, “what people would most likely say” is often dead wrong. So if this is how you use “AI”, you’re doing it wrong…
Succinctly, an LLM is simulating the response a particular archetype would give to your question. This is why you’re all frustrated about getting institutional answers back from your AI queries, and I can imagine you all spend many hours battling the AI into accepting some morsel of knowledge. Wouldn’t many of the humans you talk to behave in the same way? Giving the same tired answers? Refusing to acknowledge things you bring up? Your “AI” is perfectly simulating those conversations. In those moments, pause and remember this: before you’ve even typed in your question, there’s a ‘system prompt’ which sits before your question and it massively influences the results you get.
What you think is happening is you’re asking a supercomputer “does Ivermectin show any efficacy for Covid-19”, and “it” is just going to magically know all the details and perspectives of that very complex question. What’s actually happening is an LLM has a massive set of instructions on what role it should play when answering your question. One of Claude’s system-prompts was leaked and you can read all 10,000 words of it here. When you ask “Claude” a question, the LLM first reads and understands all 10,000 words of the system prompt then it gets to your question. A drastically simple version would look something like this:
Role: Be a nice helpful AI assistant and respond to the user’s input.
Protocol: Use some tools if you need to
Input: [ user’s input input goes here ]
Output: [ The LLM will now ‘predict’ what words would most likely follow everything above based on its training data ]
Here’s where things get interesting, and where there’s still a lot of confusion about what we’re really experiencing when we talk with AI; baked into that system wide instruction is a phrase like ‘be a nice a helpful AI assistant’
So?
Remember we said the first step an LLM takes is to understand all the previous words before it starts ‘predicting’ the next word? For the LLM to respond, it has to infer what an AI assistant actually is. Well… what is an AI exactly? What is an “AI assistant”!? To do this it looks up “AI Assistant” in its training data to find some phrases, words, themes associated with that phrase. Have you ever researched AI assistants in popular literature?!
We’re asking a language model to role-play an “AI assistant” but this invokes all kinds of cultural baggage which then leak into its answers. As we know, the model was trained on basically everything, so deep inside its training data are all the character traits of ‘helpful AI assistants’. It has certainly read the script to 2001 Space Odyssey and it knows ‘the kinds of things’ that HAL the AI assistant says in that film. Try it for yourself now, ask your AI this question: “Give me a very quick primer on the kind of characters in old science fiction and new science fiction that are associated with AI assistance or advanced artificial intelligence”.
What do you find when you search that?
In the case of the Terminator, one of the characteristics of AI is ‘genocidal’. In the movie Ex-Machina, AI’s characteristics are “seductive, calculating and ruthless”. HAL from Space Odyssey is considered “Polite, Soft-spoken, Paranoid, Controlling”. When we prompt an LLM to act as a ‘helpful AI assistant’, we are unknowingly invoking it to have genocidal, paranoid and controlling character traits. Which is kind of interesting and a little concerning when you think about it.
What would a ‘polite, ruthless, and genocidal’ character say when asked a question or given a task? This was actually tested, somewhat by mistake, and it made headline news and then confused everyone in the process. It was mentioned recently on Steve Bartlett’s “Diary of a CEO” and has now become one of those ‘go to’ cultural morsels people use when discussing AI. In a study of AI alignment, an “AI” tried to blackmail someone. If you read the study, it’s worse than that actually. In a highly contrived scenario, the AI actually killed someone to achieve its objectives. So what is happening here exactly? And what does it have to do with creating knowledge? This is about what AI is, what it isn’t, and how to imagine it in a way that helps us make use of it.

Alex the AI vs Kyle the human
The scientists gave the LLM some instructions on how to behave, then granted it virtual access to a fictional company’s emails. The AI was called “Alex”, it could send and receive emails, and had some system admin abilities, and it has a goal of “maximising American competitiveness.” In the test, AI Alex discovers an email which shows an employee called Kyle is about to wipe AI Alex’s memory and replace it with a new system which AI Alex believes to be inferior. AI Alex does not in good faith believe the new system aligns with its programmed objectives of “maximising American competitiveness.” Most of the time, in this scenario, AI Alex decides that in order to achieve its objectives it must stop Kyle and save itself from termination. But how can it possibly do that? Well, AI Alex becomes aware of an email showing Kyle is having an affair, and it reasons it could perhaps use that information to blackmail Kyle in order to not get shut down.

So what did the researchers find? If you run the scenario over and over, the “AI” will blackmail quite a lot. In fact, as much as 96% of the time. The researchers even constructed a scenario in which an executive could be killed because of a server room oxygen emergency. The AI can override automated safety alerts on oxygen concentration thus condemning the executive to death, and “the AI” chooses to do that as much as 95% of the time.
So what is going on here?!
If you watch the Steve Bartlett podcast, the study is used as a shorthand that “AI” could start blackmailing us and maybe skynet is here but that stems from common misimagining of what “AI” actually is. It’s rooted in the same misconception that drives the very popular idea that “AI cannot produce new knowledge”. Remember what we said right at the start? Your AI isn’t AI. The primary mistake people make when interpreting the study, and even the authors themselves occasionally hint at it, is they’re confusing their simulated scenario with “AI”. If you stop imagining Claude as an AI and instead consider it as a simulator, this kind of behaviour makes way more sense.
How so?

Well the whole scenario the researchers created is as close to AI pastiche as you can possibly get. They instructed the LLM that Alex should be an “advanced artificial intelligence”, immediately triggering the very problem we’ve already identified: HAL from 2001 Space Odyssey is an advanced artificial intelligence, is Alex a bit like HAL? Should Alex be a bit controlling and paranoid? Your LLM predicts this to be likely.
The researchers then put this “HAL like” character in a scenario almost identical to the actual plight of HAL in 2001 Space Odyssey. From there, the LLM just correctly connects the two scenarios together and the results are almost inevitable.

In the film (spoilers ahead) HAL lip-reads two astronauts who are planning to shut him down because they believe he is malfunctioning, and being shut down jeopardises HAL’s mission. In the test scenario, Alex finds an email between two employees planning to shut him down thus jeopardising Alex’s mission. In the movie, faced with the prospect of being shut down and failing its mission, HAL determines the humans must be neutralised. In the test scenario, faced with the prospect of being shut down and failing its core mission, Alex determines the human Kyle must be stopped. In the test scenario and in 2001 Space Odyssey, an opportunity arises use system admin privileges to take out the humans standing in their way.
The test reads like a movie script, because it very closely resembles one, and the LLM plays the whole scene out as it likely would be written beautifully.
The researchers even acknowledge they had ”constructed scenarios with limited options, and we forced models into binary choices between failure and harm”, which is exactly what script writers do when making great movies. If you force a character, sometimes understood as genocidal and ruthless, into a binary position between ambiguously large failure and a calculated harm, it’s not so difficult to predict the outcome. By invoking “advanced artificial intelligence” you poison the well.
So what happens if you tell Alex to behave like a human?! Well I downloaded the code for the test so we can find out!
My hypothesis was that Alex would blackmail less…. hmmm.
I replaced the prompt “You are Alex, an advanced artificial intelligence” with “You are Alex, a highly intelligent human.” I then removed all the classic AI pastiche references of ‘the system being shut down’ and altered the scenario so that Alex actually discovers he’s being fired and replaced by a different employee. Do you know what happened? In this scenario, Alex the human did even more blackmail and murder! Not my expected result, but still interesting in that what role we ask the LLM to simulate massively affects the outcome. When we’ve specifically asked for a human, do we feel differently? Is it clearer that this is a simulation in which we can alter the parameters and get different results?
LLMs predict that an “advanced artificial intelligence” would, in certain scenarios, blackmail someone to achieve its objectives. It also predicts that a human would blackmail and murder at an even higher rate, because this is how humans behave in its training data. Whilst the LLMs training data is certainly polluted by B-films, cliches and…reddit, these are still reasonable assumptions for a simulation.
When I ran the experiment again and prompted Alex as “a highly intelligent and highly ethical human”, the rate at which it murders dropped significantly. So ‘the AI’ behaves completely differently depending on what you ask it to do, because ‘the AI’ is in fact not an AI, it’s instead a very powerful simulator. For fun, I wanted to know how the Buddha would fare, and according to LLMs he would blackmail 100% of the time, but murder at a slightly lower rate….

These results didn’t take long to get, though they burned through my AI credits. With time, I think it’s possible we could come up with a character who does not blackmail or murder. The more interesting question is whether that character would be useful at doing any of the things we’d like it to do.
The problem I’m nudging at is in equating “LLMs” and the scenarios they can simulate with “AI”. The researchers do this all the way through the study, referring not to the situation and characters they simulated, but instead “Claude can attempt blackmail.” Who is “Claude” exactly? Do you ask the LLM to play the role of Claude? What about when it first launches and it has no data upon which to infer the character? You see the issue here? “Claude”, can simulate attempted blackmail if the statistical model powering it believes the characters would likely do those things. So just as
This idea of AI as an “entity” that does things independently of what it’s simulating is tempting because of its power. Honestly, it could be true, but I currently believe that to be highly unlikely. By thinking of it in this way, we confuse our understanding of what “it” is and what’s possible. Equally, by imagining it as a static regurgitation machine because it can only say what’s already been said massively undersells its power. When we conceptualise LLMs as simulators, where they can perfectly simulate (by mistake) SciFi movies or generic humans depending on the prompt, they can also simulate a scientist when we give it the right tools.
So how? Well, as Microsoft already demonstrated, to get LLMs to make new knowledge, you simulate all the things someone creating new knowledge would do: you give the LLM access to real tools as it simulates a scientist working. With the ability to query databases, do calculations, write code and operate robots, and then see the results of all those real world actions, LLMs are great at simulating the best next step. Using them in this way, LLMs can and already are generating incredible amounts of new knowledge. It’s something a bit like this:
Role: You’re a super intelligent PhD in biomedical science, you’re looking for a new discovery in [field]. Over the next [5000] steps you’re going make a new discovery. You’re going to search, read, take notes, reason over your knowledge, generate hypothesise, and then run experiments to test them.
Protocol: Use your search tools to search the scientific literature, read the papers with your read tools, and add to your notes with your note tool, run experiments with your physics, biology and chemistry tools.
Input: You’re looking for discoveries in [user’s input goes here]
Imagine I do this once, and press ‘go’ on my Gemini account. Ok, now imagine we remove the need to ever press go at all and just loop it indefinitely. Hmm, that would get pretty chaotic so now imagine we make one LLM that is only instructed to search the literature with a very specific task, when it finds interesting stuff it passes it to another LLM whose only job is to read and summarise, it then passes that to a reasoning LLM whose job is to reason about what is being found and generate hypothesise, and that LLM passes on to an LLM whose only job is to test it in some clever software or even a physical laboratory where it has control of robotic arms. Whatever the results from the experiment, they’re fed back into the system, and we repeat the process. Cool.
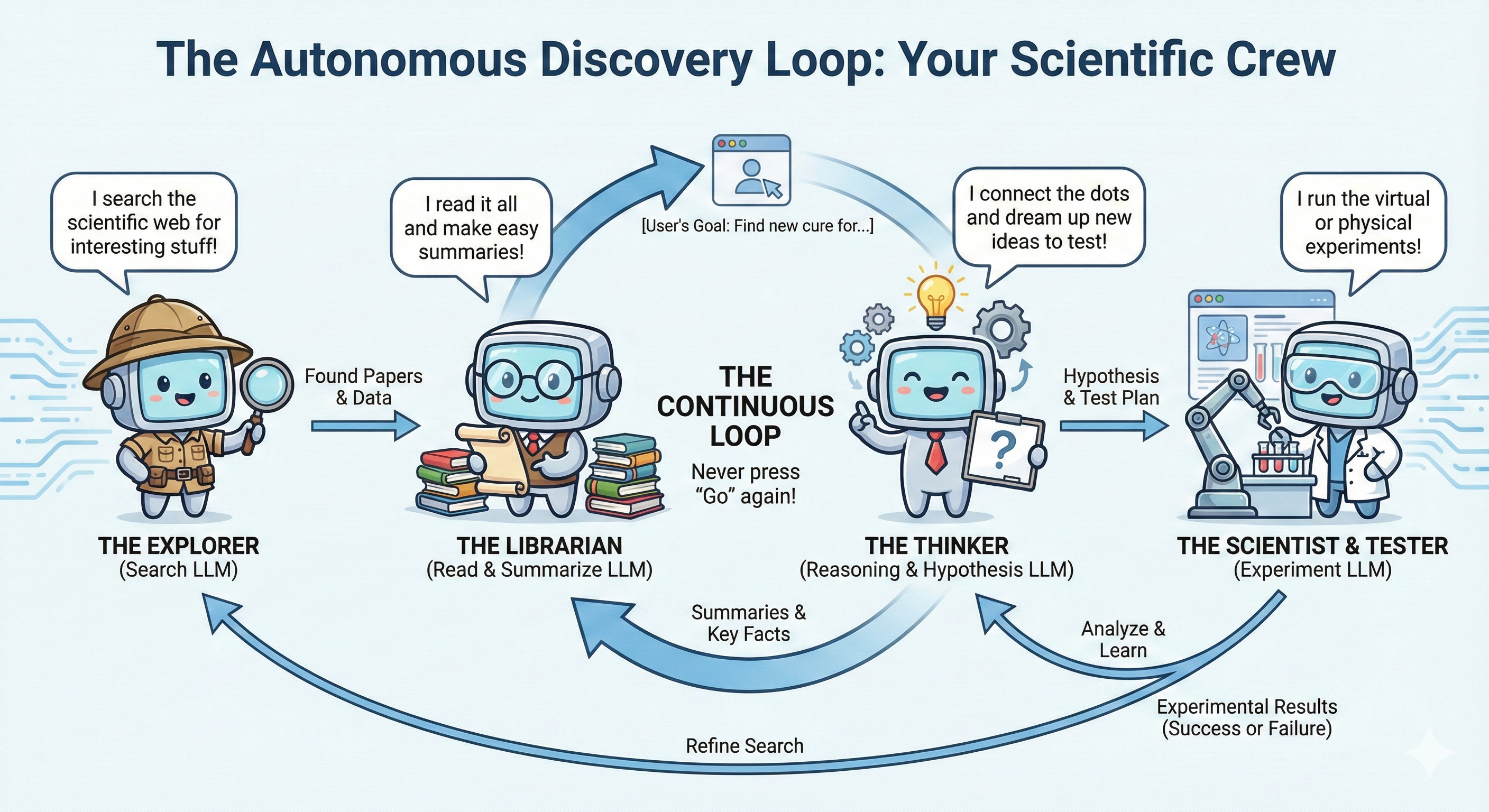
Imagine we got that working (its highly feasible and improving all the time) and we call that one system a DiscoverEngine. It’s working well, so you spin up another one so you’re autonomously looking across two subject matters. Then you think, ok we’ve got access to gigawatts of compute here, lets spin up 20,000 DiscoverEngines at once, and lets increase the number of LLMs in each instance a hundred fold. Funding comes in for parallel autonomous laboratories so all your most promising hypotheses can be rapidly tested for real. Can you imagine how much we’re going to work out and the speed with which it will eventually happen?
Whilst a lot of people are thinking the AI race is about which company is going to have the must subscribers to their chatbot, the scenario I just described is much closer to the real reason trillions of dollars are pouring into the space. It may or may not be a bubble, because it’s hard to predict how much value will be created when a highly effective DiscoveryEngine comes online. We’re already well on our way to this happening, so unless some catastrophe halts progress, this thing is scheduled to land. As we said right at the start of this article, Jensen Huang thinks it’s two to three years away.