



There's no evidence of X
How the data hides in plain sight

Hello everyone. I’m still here.
I’ve built something I’m pleased with, it’s ready for you to use and I want to tell you about it. If you want to skip right ahead to case.science at the bottom.
The last three years were a strange time. Our society has changed for good, partly for the better, partly for the worse. For many of us, myself included, our strategy to make sense of the world has drastically changed. Inside the shifting sands is something I noticed long ago; we are rarely hearing each other. To some degree, you have your perspective, I have mine, and there’s no easy way to break the impasse.
Can we break the inertia?
Take any contested subject matter. If you wanted a quick rundown, you could head to Wikipedia, look it up, and you’ll get something resembling a consensus position. It’s an incredible platform, but because of its tendency towards “the current thinking”, for contested ideas, it is close to useless. A single man is responsible for one third of what’s on there, and given our hotly contested times, a single man cannot be the source of one-third of our perspective. It’s a wonderful reference database of current thinking, but it is not a fertile battleground for thrashing out new ideas.
On Twitter, the problem is compounded by tribalism. The shortened character limits make it a very adversarial platform where conversations rapidly descend into arguments and insults. Twitter Spaces are a step in the right direction, but they’re not easily scalable to a large audience, and the unedited replays can be long, ambling, rambly and niche. It’s also very transient. Maybe a fruitful conversation did illuminate an issue beautifully, but how many people were tagged in it? Did they read it all? It often gets lost in the ether.
Whilst the tribalism may manifest on Twitter in its most opaque form, it’s not the source of the issue. Climbing down from a perspective that turns out to be wrong isn’t easy, and the problem is especially apparent if you’re sitting in a research department dedicated to having that perspective.
There’s a crutch I’ve found.
When a core belief is challenged, I’ve noticed a pattern time and time again. It’s a crutch that people and institutions use, and it goes something like this: they will boldly state, “There’s no evidence of X.” You can substitute X for any idea that might open a can of worms. It’s a remarkably common phrase, and it has more power than you might think. We’re social creatures, our desire to rub along and get on is outstripped by our need to integrate a challenging truth. So what happens when institutions drop this trick on us? We can’t and don’t test each and every statement an ‘authoritative’ body makes. Trust is a very real component of any relationship, and that is especially true of our institutions. We understand these institutions as trusted arbiters of our complex reality, so when they talk, we tend to listen. When they say there’s no evidence of X, people believe them. The statement works.

This is an example I picked at random, but it’s a good one. At the time when the ‘trusted’ WHO made this bold comment, there was evidence of AstraZeneca Covid Vaccine problems because the German healthcare system had used that very evidence to suspend the use of the vaccine. The WHO made the statement anyway.
Nifty eh?
The “No evidence of X” trick is a great way to keep a sacred perspective intact. In this case, the “golden goose” is that vaccines can only ever be perfectly safe regardless of when, who, how, or what is being injected. Drugs, sure, maybe we can debate their safety under very strict circumstances, but if that drug is administered with a needle, then it’s a vaccine, and vaccines are always safe. Always. Something like that.
“When an honest man discovers he is mistaken, he will either cease being mistaken, or he will cease being honest.”
Anonymous
It’s not just in medical science that the phrase is used; it has massive utility right across our society. Take a look through Google for exact hits on the phrase and you’ll find a fascinating portfolio of its use-cases. It’s a functioning and highly utilised jedi mind trick: state the magic words confidently enough and you’ll leave well-meaning people with the opinion that there really is no evidence of [insert challenging idea here].

But as many of us here on this substack saw, there was evidence of vaccine harm long before the regulators reluctantly admitted it. There was evidence that generic drugs were a useful tool in the fight against Coronavirus, and there was evidence that would suggest the virus emerged from a botched gain-of-function study in Wuhan.
The Jedi mind tricks don’t eliminate the evidence, they just eliminate enough of the public’s desire to look for it that it no longer matters. After all, if it’s not there, why look?
Is there a solution?
A few months ago I tried to address the “No evidence of X” problem by personally translating some of that apparently non-existent evidence into a format that a wider audience could engage with. It worked. Data that would ordinarily remain in a niche medical journal, in incredibly difficult prose, found a new audience of interested laypeople. “Evidence of X” had emerged from the shadows! It inspired an idea: what if I could use AI to do this at scale? Maybe then we could move the dial?
With that in mind, I set to work and built openpaper.science. I told you all about it here on The Digger. It’s a tool that takes scientific papers and uses AI to translate them into a readable ‘lay’ summary. It worked great.
I was pleased, but the project just didn’t feel complete. The summaries were great, but our society is producing so much data that even choosing what to translate becomes a very difficult task. The data needed to be organised in a way that addressed the ‘No evidence of X’ problem. That way, we could still disagree on twitter, but the power of the “No evidence of X” trick would be greatly diminished by a nice repository of all the data currently supporting X.
And so that is exactly what I’ve built. I’m pleased with it, and it’s ready for you to use right now. The project is called case.science and I’d love to tell you how it works.
Case.science
The front page displays all the latest ‘cases’ submitted by case.science users. A case is simply a statement that you believe to be true, with a short description of the case you’re trying to make.

Making a Case is easy. What are you trying to demonstrate to be true? Type that into the title and then give your case a description. Your case is ready to go! So now what happens?
You must now add sources to your case. Sources are links on the internet that support your the assertion you’ve made in the case. They can be articles, tweets, or science papers. Soon you’ll be able to add videos, podcasts, and documents.
When you add a source to support your case, the system processes it, and an AI then reads and understands the data in that source. It’s very cool.
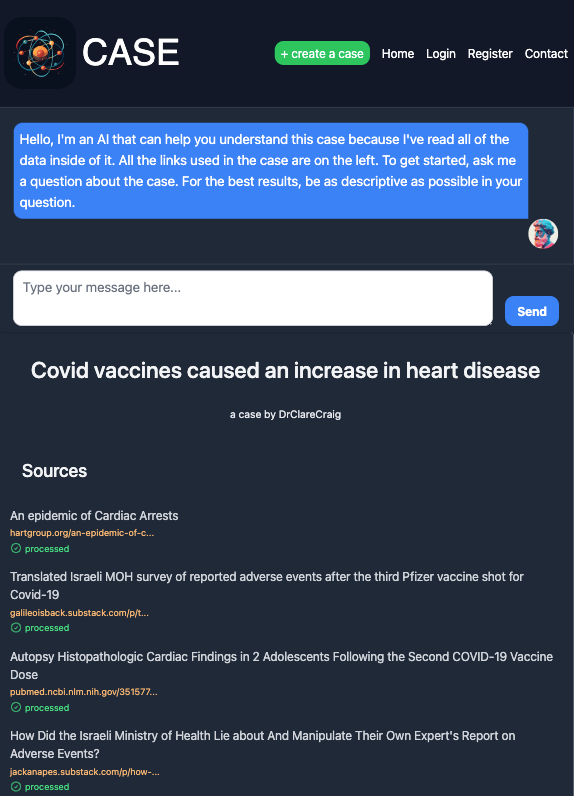
The AI will now argue that case to the best of its ability to anyone who has any questions about it. Share the link with anyone, and they can ‘talk’ with the data inside it.
The rules of case.science prevent the AI from using any data other than what is inside the case to form its arguments. I’ll say that again. The AI can only form arguments from data inside the case you’ve built.
When the AI responds with an answer to your question, it will show you where it sourced that answer by highlighting the source in green.
You can click on the source and read it for yourself.
That’s it.
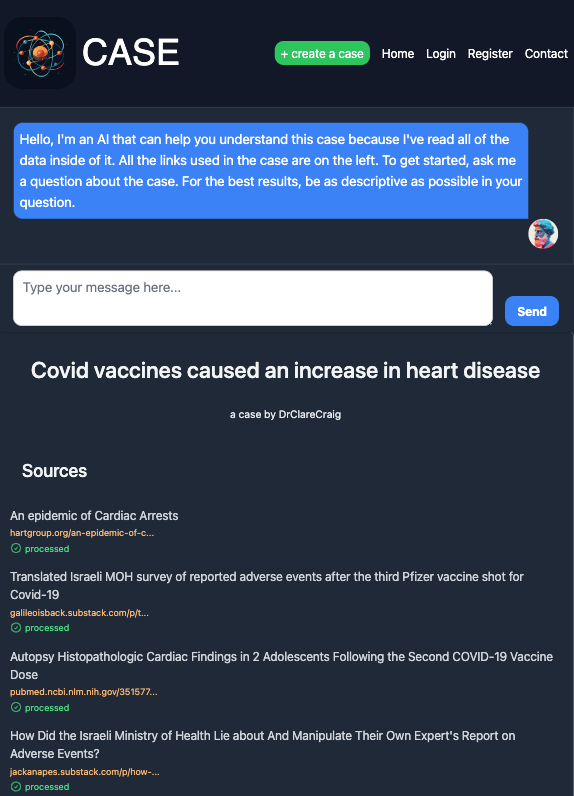
I designed the system to be simple, flexible, and powerful. You can make a case about anything. You can use it in a whole range of ways, hopefully in ways I’ve not even thought about yet. One great thing about Case is that you can share your case immediately. The moment it’s created, the link is sharable. Each time you add a source to your case, the system will attempt to process it immediately, and within a minute or so you should be able to ‘talk’ with that source and how it relates to the case you’re trying to make.
One of the biggest problems we have with exciting advances of AI is that we don’t know the ways in which they’ve been ‘pre-prompted’ to give certain ‘current thinking’ answers. Case.science addresses this problem head-on. The data it’s using to formulate the answers is right there inside the case. Cases are open and transparent. They are user-generated repositories of data that support a particular assertion, and the AI uses that data and only that data, to argue the case.
Case is actually biased by design, because its designed to argue the case your gave it to the best of its ability. It’s similar to the way criminal law works, a defence lawyer and the prosecuting lawyer are biased towards their client, but this is the point. If you don’t like the one-sidedness of a case, it’s contingent upon you to make an inversion of that case.
If someone has made a case that the sky is blue, you can make a case that the sky is red. In future versions, opposing cases will be able to ‘duke it out’ in something very much resembling a public AI courtroom. There are many ways in which this tool can grow from where it’s at right now.
It’s ready to use
To get things started, Dr Clare Craig has put together a case with 96 sources in which she argues that the rollout of the COVID vaccines has caused an increase in heart disease. You can talk with that case right now at this link.
https://case.science/case/16
Things are early with the project, so for now I have to keep the ‘creation’ of cases restricted whilst I test the code. If you’re a paid subscriber to The Digger, there’s an invitation waiting at case.science/register. You have supported the creation of this tool which I hope can raise the quality of the discussion in our global village. Paid subscribers can make a Case right now, just make sure to sign up using the same email address you use for The Digger. If you have any trouble, please let me know in the comments of this article. If you’re a free subscriber, you’re supporting this too. Right now, you can talk with the cases available, which are already live at case.science. As ever, shares are always appreciated. Comments are open on this thread.
So now what?
I am going to be building cases using the tool, and I’ll be writing companion pieces to go with them here on The Digger. In the coming weeks, I also aim to run a series of podcasts with some ‘out there’ thinkers. They’ll explain their ideas to me in a 30-minute podcast format, and all the supporting articles, references and documents will go into a case at case.science.
I also want you, subscribers of The Digger, to start putting cases together on case.science. Whilst the project has been born out of frustration with the gap between medical publishing and public knowledge, I don’t want this to be the sole focus. In fact, it cannot be the sole focus. There is a whole range of topics, ideas, statements, cases and arguments that case.science can help with. The simplicity of writing a case & description, adding sources and then immediately sharing it means there’s a whole range of ways in which the tool can be used.
Right now, a narrow and demonstrable title, along with a tight description of the case works very well. The quality and relevance of the sources supporting your case is very important. If they are relevant and well-written, the system works very well. I will be heavily moderating the cases, because I’ve been on the internet long enough to know what happens when when the guardrails come off. If you have questions, you can ask them of me either by replying to the email or as a comment.
If you know of some way to help with the project, get in touch.
Comments open.
This is awesome! Thanks for developing this!
great idea! please try to secure your software from external attacks, when it goes viral it will attract some of that unwanted attention from piwerful censors